
使用流程:
一、下载llama.cpp windows版本的exe程序
https://github.com/ggml-org/llama.cpp/releases
二、下载GGUF格式的模型文件,跟llama放在同一个目录
https://huggingface.co/models?sort=trending&search=Qwen3.5
三、打开CMD,或者在LLama目录 直接运行CMD
#命令行交互方式 llama-cli -m Qwen3.5-0.8B-BF16.gguf #webui界面交互方式 llama-server -m Qwen3.5-0.8B-BF16.gguf --port 8080 llama-server -m Qwen3.5-35B-A3B-UD-IQ3_S.gguf -c 8192 -ngl 999 --port 8080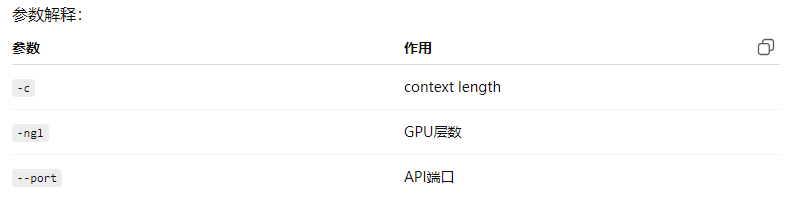
 赞
赞 

 打赏
打赏  生成海报
生成海报 

高效运行。它最初为 Meta 的 LLaMA 模型设计,如今已支持 Mistral、Llama 2/3、Qwen、Phi 等主流开源大模型,通过量化(INT4/INT8/FP16)、SIMD 优化、内存复用等技术,实现“低资源占用+高速推理”的平衡。)
高效运行。它最初为 Meta 的 LLaMA 模型设计,如今已支持 Mistral、Llama 2/3、Qwen、Phi 等主流开源大模型,通过量化(INT4/INT8/FP16)、SIMD 优化、内存复用等技术,实现“低资源占用+高速推理”的平衡。&summary=llama.cpp 是一个轻量级、高性能的 C/C++ 开源框架,核心目标是让大模型在端侧设备(PC、嵌入式设备、边缘服务器)高效运行。它最初为 Meta 的 LLaMA 模型设计,如今已支持 Mistral、Llama 2/3、Qwen、Phi 等主流开源大模型,通过量化(INT4/INT8/FP16)、SIMD 优化、内存复用等技术,实现“低资源占用+高速推理”的平衡。&site=%E6%9E%9C%E6%A0%B8%E5%89%A5%E5%A3%B3&pics=/upfile/2024/08/1724916605116.jpg)













发表回复
评论列表(0条)